
Redis的优势
速度快
单机读可达10000/S, 写可达 5000/s。RDS巨擘mysql ,基本单机为1000/500。
为什么快
redis 是操作内存,操作速度自然比mysql的磁盘操作要快。其次是因为数据存储结构的原因。
数据结构
Redis是内存中的数据结构存储系统。支持5种基本结构:String,List,Set,Sorted set,Hash。
1、sds
其中底层是通过SDS(simple dynamic string)动态字符串来实现,与java c的字符串不同,他的定义是不单单是一个char 数组构成,每个sds都会比它真实占用的字符长度都长,通过一个空闲标识符表示sds当前空闲字符有多少,如此设计,在一定长度范围的内的字符串都可以使用此sds,而且不会频繁的进行内存分配,直到此sds不能容纳分配的字符串,如果遇到这种情况情况,才需要进行扩扩容。
所有的redis k-v 中的字符串都是依托于sds,这是其一;
2、dict
其二 dict,每个dict拥有两个数组,一个简单的hash算法;
redis为了保证最快的执行速度,hash就是可以和一个定值运算。为了扩容,所以有两个dict数据。初始的dic的数组长度不能太大,随着数据的增加,超过了负载因子,dic的数组必须进行扩容
dict扩容方式
hashMap的扩容方式是:新生一个更长的数组,遍历老数组向新数组的迁移。
dict的扩容是渐进式的,扩容过程中不影响当前使用dict数组正常使用,一点点划拉,直到迁移完成,
3、索引结构
Redis使用跳跃表,其在随机搜索方面略低于B+树,但是对于数据插入,跳跃表使用了历史上最屌的算法:抛硬币。
在跳跃表是由N层链表组成,最底层是最完整的的数据,每次数据插入,率先进入到这个链表(有序的),插入完成后,通过抛硬币的算法,判断是否将数据向上层跑,如果是1的话,就抛到上层,然后继续抛硬盘,判断是否继续向上层抛,直到抛出了0结束整个操作,每抛到一层的时候,如果当前层没有数据,就构造一个链表,将数据放进去,然后使用指针指向来源地址,就这样依次类推,形成了跳跃表,每次查询,从最上层遍历查询,如果找到就返回结果,否则就在此层找到最接近查询的值,将查询操作移到另外一层。
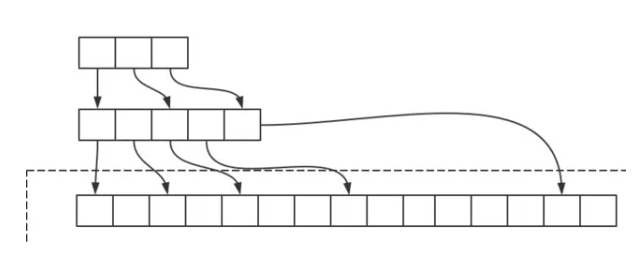
4、存储方式
redis存储方面巧妙的地方之一,更主要是单线程+多路 I/O 复用模型。
单线程
单线程的模式解决了数据存储的顽疾:数据并发安全,任何运行多线程同时访问数据库都会存在这个问题,所以才有了mysql的mvcc和锁, Memcached 的cas 乐观锁,来保证数据不会出现并发导致的数据问题,但是redis 使用单线程就不存在这个问题:1,单线程足够简单,无论在redis的实现还是作为调用方,都不需要为数据并发提心吊胆,不需要加锁。 2.不会出现不必要的线程调度,你知道多线程,频繁切换上下文,也会带来很多性能消耗
多路 I/O 复用模型
这个也是java 的NIO体系使用的IO模型,也是linux诸多IO模型中的一种,说白了就是当一个请求来访问redis后,redis去组织数据要返回给请求,这个时间段,redis的请求入口不是阻塞的,其他请求可以继续向redis发送请求,等到redis io流完成后,再向调用者返回数据,这样一来,单线程也不怕会影响速度了
如何避免缓存击穿
缓存一般作为RDS的前置系统和服务器直连,减轻rds的负担,常理而言,如果服务器查询缓存而不得的话,需要从rds中获取然后更新到缓存中,但是如果在“从rds中获取然后更新到缓存中”,这个阶段,缓存尚未更新成功,大量请求进来的话,rds势必压力暴增,甚至雪崩,或者歹人恶意攻击,一直查询rds和缓存中未存在key,也会导致缓存机制失效,rds压力暴增,称之为缓存击穿
防止缓存击穿的几种方式:
- 缓存永不失效;
- 定时同步rds redis;
- 不允许应用直接请求查询rds,所有的查询以缓存中为准;
